NOTE: Demo visuals use either blurred real data or synthetic placeholders to protect customer privacy.
Manual Optimization Is a Bottleneck
Behind every Abnormal product is a massive infrastructure footprint, and optimizing that footprint matters. From compute costs to runtime efficiency, small improvements at scale translate into major savings.
To tackle that challenge, Daniel Ferstay built an AI-driven service optimization workflow that teaches AI how to analyze system profiles, recommend improvements, and even right-size infrastructure automatically. The result: a faster, cheaper, and smarter way to optimize code across Abnormal’s platform.
Abnormal’s services run across Amazon EC2, and compute costs add up quickly. EC2 usage accounts for roughly 30% of total infrastructure spend, proportional to the number of services deployed and the resources they consume.
As Abnormal continues expanding into new environments, each with its own service stack, optimization has become increasingly critical. But traditional optimization workflows are slow and resource-intensive:
- Complex analysis: Interpreting performance profiles requires expert-level knowledge of tools like pprof and flame graphs.
- Iterative process: Engineers must repeatedly pull profiles, diagnose hotspots, deploy fixes, and re-measure performance.
- Limited scale: Only a few experienced engineers can perform this level of optimization effectively.
Optimization isn’t a one-time task; it's a cycle. Each round of analysis takes time, and every service adds more to the queue. The question became clear: Could AI help scale optimization without sacrificing quality?
AI-Driven Optimization from Code to Container
Daniel built a workflow that uses Claude, integrated into Abnormal’s Nora-pr (Nora Pull Request) tool, to automate the most time-consuming steps of service optimization.
Here’s how it works:
- Feed the AI a profile: Engineers provide a heap dump or flame graph from a running service. Using a new commit-file option in Nora-pr, they attach this file directly to the pull request command.
- Give Claude a goal: Example prompt, “Reduce memory usage of this service using the attached heap dump to identify the largest source of allocated memory.”
- Claude runs the analysis: It inspects the profile, identifies allocation hotspots, and recommends code optimizations. It then creates a pull request with targeted changes, such as introducing object pooling or caching mechanisms.
- Engineers review and learn: Claude’s output doesn’t just modify code; it explains why each change works, teaching engineers optimization principles along the way.
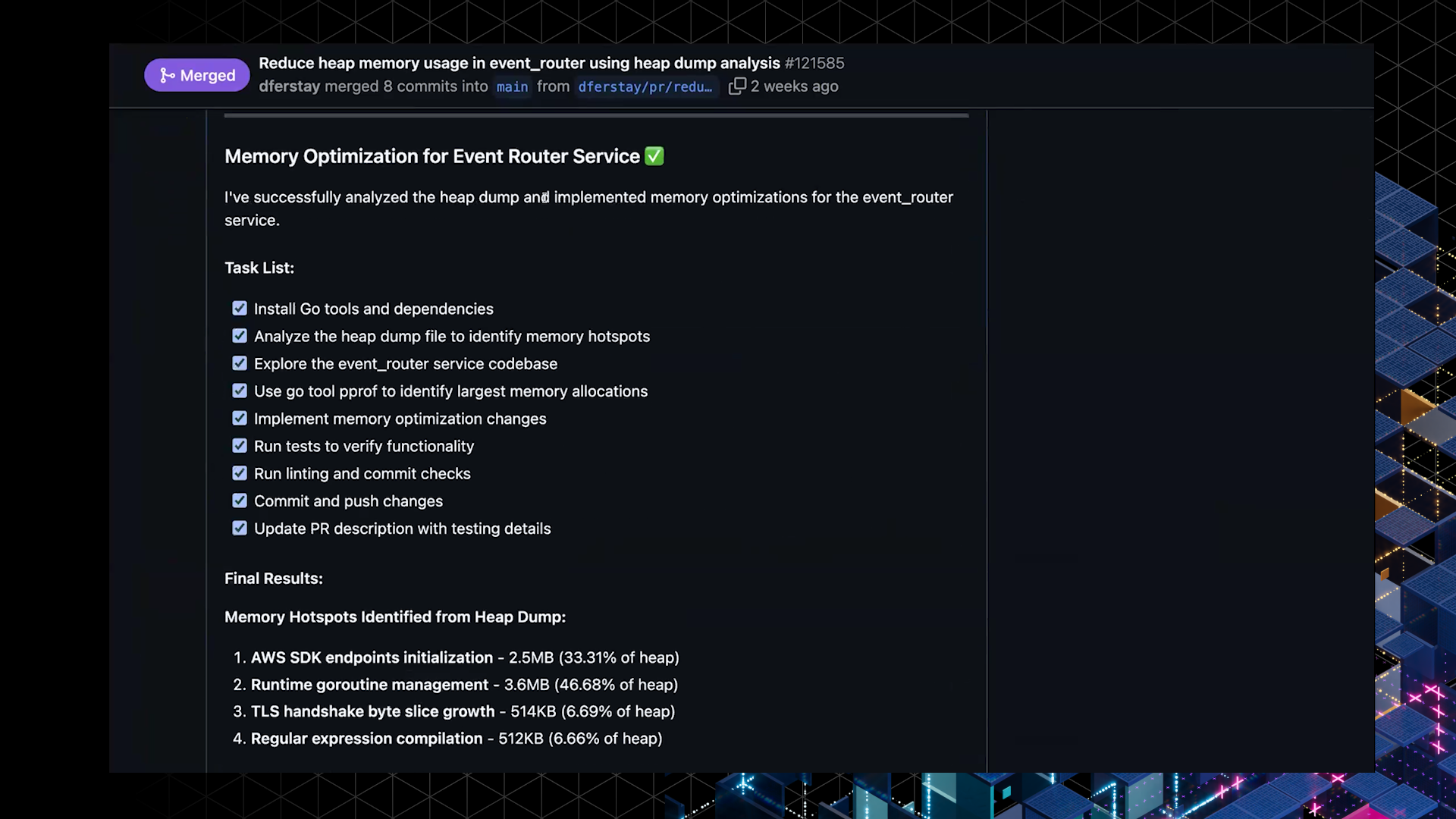
In one demo, Claude identified excessive array allocations in a service and replaced them with an object pool, reducing redundant memory usage. It also added caching logic to avoid recomputation of frequently used values.
Real Optimization, Real Savings
The results were immediate and measurable.
- Memory usage dropped by 50% after the AI’s optimizations.
- Claude’s changes were educational, helping junior engineers understand common optimization strategies.
- The workflow was simple to scale, enabling performance improvements across multiple services without deep manual analysis.
This approach doesn’t just fix inefficiencies; it creates a learning loop where AI and engineers collaborate to make each service faster and more cost-effective.
Right-Sizing Infrastructure Automatically
In the latest version, Daniel extended the workflow to handle infrastructure optimization as well.
Using the same commit-file option, engineers can now attach utilization screenshots, such as 7-day CPU or memory charts from service dashboards, and prompt Claude to right-size container resource requests.
Example: “Right-size the container resource requests for this service using the attached screenshot of CPU and memory utilization.”
Claude interprets the chart, locates the relevant manifest file, and adjusts configuration values accordingly. In one test, it:
- Reduced CPU requests from 500 millicores to 50 millicores
- Reduced memory requests from 512MB to 128MB
This means lower idle resource allocation and significant COGS (Cost of Goods Sold) savings at scale.
AI as an Optimization Partner
This workflow shows how AI can collaborate with engineers, not just automate them.
- Offloads complex tasks: AI handles the hardest parts of performance tuning, freeing engineers to focus on higher-level improvements.
- Educates through output: Each PR includes detailed reasoning behind the changes, creating instant mentorship moments.
- Scales easily: The same workflow can run across dozens of services, each generating measurable efficiency gains.
- 50% reduction in memory usage in test cases
- Significant infrastructure cost savings through automated container right-sizing
- Reusable process that can scale across all R&D teams
The workflow also lays the foundation for a company-wide shift: making optimization accessible to every engineer, not just performance experts.
Automating the Full Optimization Loop
Daniel’s next step is to fully automate the workflow:
- Auto-collect service profiles: Script the process of gathering heap dumps and dashboards from running programs.
- One-shot PR creation: Automatically generate PRs that include analysis files and recommendations in a single step.
- Deeper integration with observability tools: Feed metrics directly from Grafana or CloudWatch to drive even smarter recommendations.
With these upgrades, Abnormal could reach a future where every service continuously optimizes itself, with AI spotting inefficiencies and proposing fixes autonomously.
What Makes AI Optimization of AWS Compute Speed Awesome
Daniel’s AI-Driven Optimization Workflow is a perfect example of how Abnormal engineers use AI to make technical excellence scalable. By merging infrastructure know-how with intelligent automation, he built a system that not only saves money but teaches better engineering practices in the process.
It’s innovation that multiplies impact, making both code and engineers more efficient with every iteration.
