NOTE: Demo visuals use either blurred real data or synthetic placeholders to protect customer privacy.
Closing the Incident Loop
Incidents do not end when traffic comes back. The hard part is capturing what happened, why it happened, and what to change, even when the on-call team is drained and ready to move on. At Abnormal, that means filling out a structured post-mortem template with timelines, dwell time, “Five Whys,” and action items that often become Jira tickets.

Three frictions showed up repeatedly:
- Fatigue after resolution: once the incident is over, there is pressure to write quickly, even if the response ran late.
- Evidence scavenger hunt: engineers bounce between Slack threads, PagerDuty, Prometheus metrics, CloudWatch logs, and old Jira tickets.
- Check-the-box outcomes: teams sometimes ship vague, surface-level writeups, then do not follow the full learning process that prevents repeats.
Agent-Assisted Post-Mortems
Nora is an AI solution that takes a raw “data dump” collected during incident response and turns it into a post-mortem that matches Abnormal’s template. Instead of asking an engineer to manually stitch together timestamps, links, and context, the agent gathers signals directly from connected systems and drafts a complete Markdown document that can be converted into a Confluence page.
Key capabilities include:
- Ingest raw context: accepts pasted links, notes, Slack thread text, and incident breadcrumbs from a working doc or channel.
- Pull telemetry automatically: fetches supporting details from Slack, PagerDuty, Prometheus, and CloudWatch.
- Add deployment-level depth: can trace a mentioned deployment or PR to a specific GitHub artifact and include the relevant link and timing.
- Structure to the template: generates the required sections consistently, then runs lightweight validation for template adherence.
- Improve causal rigor: flags weak causal reasoning and can prompt for follow-ups before the write-up is finalized.
As Ivan put it, “I would say, like, on average, it takes me, like, 3 hours to create a post-mortem,” and Nora aims to shift that work from manual assembly to guided review and edits.
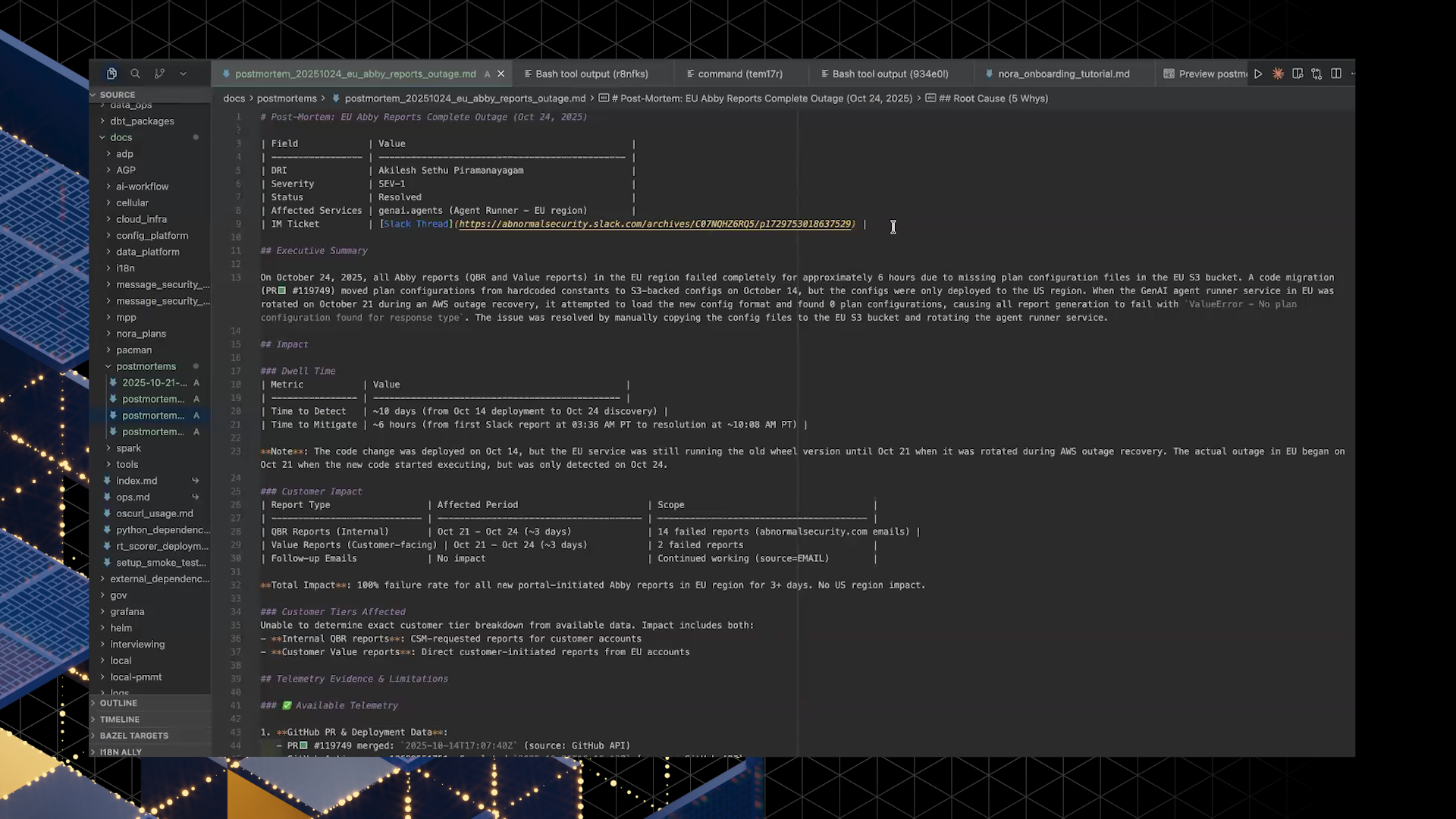
Under the hood, Ivan implemented this with a Claude agent, a hard-coded template included in the system prompt, and a Markdown-to-Confluence workflow so the output lands where engineers already keep post-mortems.
Faster, Deeper Learning Loops
Nora’s impact is less about flashy automation and more about making disciplined incident learning easier to finish. In Ivan’s demo, the agent produced a post-mortem he described as more complete than the one he originally wrote for a complex incident, especially in the timeline and “Five Whys.”
Early value shows up in a few concrete ways:
- Less active writing time: Ivan estimates that a post-mortem that used to take around 3 hours can become closer to about 30 minutes of active nudging and review.
- More complete timelines: the agent captures timestamps and incident identifiers that engineers often skip when they are tired.
- Quicker action-item flow: clearer root cause and context means Jira tickets and follow-ups can be created and addressed sooner.
- Better experience for on-call engineers: they can focus on investigation and fixes, not formatting and copy-paste.
Next step: roll Nora into more incident types and measure two things consistently, post-mortem completion time and review quality, then tighten the validation and prompts based on where humans still need to correct reasoning.
Clarity for the Whole Room
Peers called out how approachable Ivan’s walkthrough was, even for teammates who do not live in incident tooling day-to-day. That matters because post-mortems are only useful when more than one responder can understand and act on them.
The broader signal is cultural: Nora reinforces a habit that Abnormal depends on, learning from failure without adding burnout. As more teams adopt it, we should see post-mortems become easier to finish, easier to review, and more directly connected to the prevention work that keeps customers running.
